

Today I start a series of interview preparation for a data scientist in 60 days I think it’s very helpful to join as a fresher. who wants to become a data scientist.
Q1. What is the difference between AI, Data Science, ML, and DL?
Artificial Intelligence: AI is purely math and scientific exercise, but when it became computational, it started to solve human problems formalized into a subset of computer science. Artificial intelligence has changed the original computational statistics paradigm to the modern idea that machines could mimic actual human capabilities, such as decision-making and performing more “human” tasks. Modern AI is into two categories
- General AI — Planning, decision making, identifying objects, recognizing sounds, social & business transactions
- 2. Applied AI — driverless/ Autonomous car or machine smartly trade stocks
Machine Learning: Instead of engineers “teaching” or programming computers to have what they need to carry out tasks, computers could perhaps teach themselves — learn something without being explicitly programmed to do so. ML is a form of AI based on more data, and it can change actions and responses, making it more efficient, adaptable, and scalable. e.g., navigation apps and recommendation engines. Classified into:-
1. Supervised
2. Unsupervised
3. Reinforcement learning
Data Science: Data science has many tools, techniques, and algorithms called from these fields, plus others –to handle big data The goal of data science, somewhat similar to machine learning, is to make accurate predictions and to automate and perform transactions in real-time, such as purchasing internet traffic or automatically generating content.
Data science relies less on math and coding and more on data and building new systems to process the data. Relying on the fields of data integration, distributed architecture, automated machine learning, data visualization, data engineering, and automated data-driven decisions, data science can cover an entire spectrum of data processing, not only the algorithms or statistics related to data.
Deep Learning: It is a technique for implementing ML. ML provides the desired output from a given input, but DL reads the information and applies it to other data. In ML, we can easily classify the flower based on its features. Suppose you want a machine to look at an image and determine what it represents to the human eye, whether a face, flower, landscape, truck, building, etc. Machine learning is not sufficient for this task because machine learning can only produce an output from a data set — whether according to a known algorithm or based on the inherent structure of the data. You might be able to use machine learning to determine whether an image was of an “X” — a flower, say — and it would learn and get more accurate. But that output is binary (yes/no) and is dependent on the algorithm, not the data. In the image recognition case, the outcome is not binary and not dependent on the algorithm. The neural network performs MICRO calculations with computational on many layers. Neural networks also support weighting data for ‘confidence. These results in a probabilistic system, vs. deterministic, and can handle tasks that we think of as requiring more ‘human-like’ judgment.
Q2. What is the difference between Supervised learning, Unsupervised learning, and Reinforcement learning?
Ans 2:
Machine Learning
Machine learning is the scientific study of algorithms and statistical models that computer systems use to effectively perform a specific task without using explicit instructions, relying on patterns and inference instead. Building a model by learning the patterns of historical data with some relationship between data to make a data-driven prediction.
Types of Machine Learning
1-Supervised Learning
2-Unsupervised Learning
3-Reinforcement Learning
Supervised learning
In a supervised learning model, the algorithm learns on a labeled dataset, to generate reasonable predictions for the response to new data. (Forecasting outcome of new data)
• Regression
- Classification
Unsupervised learning
An unsupervised model, in contrast, provides unlabelled data that the algorithm tries to make sense of by extracting features, co-occurrence, and underlying patterns on its own. We use unsupervised learning for
- Clustering
- Anomaly detection
- Association
- Autoencoders
Reinforcement Learning
Reinforcement learning is less supervised and depends on the learning agent in determining the output solutions by arriving at different possible ways to achieve the best possible solution.
Q3. Describe the general architecture of Machine learning.
Business understanding: Understand the given use case, and also, it’s good to know more about the domain for which the use cases are built.
Data Acquisition and Understanding: Data gathering from different sources and understanding the data. Cleaning the data, handling the missing data if any, data wrangling, and EDA( Exploratory data analysis).
Modeling: Feature Engineering — scaling the data, feature selection — not all features are important. We use the backward elimination method, correlation factors, PCA, and domain knowledge to select the features.
Model Training based on trial and error method or by experience, we select the algorithm and train with the selected features. Model evaluation Accuracy of the model, confusion matrix, and cross-validation.
If accuracy is not high, to achieve higher accuracy, we tune the model…either by changing the algorithm used or by feature selection or by gathering more data, etc.
Deployment — Once the model has good accuracy, we deploy the model either in the cloud or Rasberry py, or any other place. Once we deploy, we monitor the performance of the model.
if it’s good…we go live with the model or reiterate all processes until our model performance is good. It’s not done yet! What if, after a few days, our model performs badly because of new data? In that case, we do all the processes again by collecting new data and redeploying the model.
Q4. What is Linear Regression ?
Ans 4: Linear Regression tends to establish a relationship between a dependent variable(Y) and one or more independent variables (X) by finding the best fit of the straight line. The equation for the Linear model is Y = mX+c, where m is the slope and c is the intercept
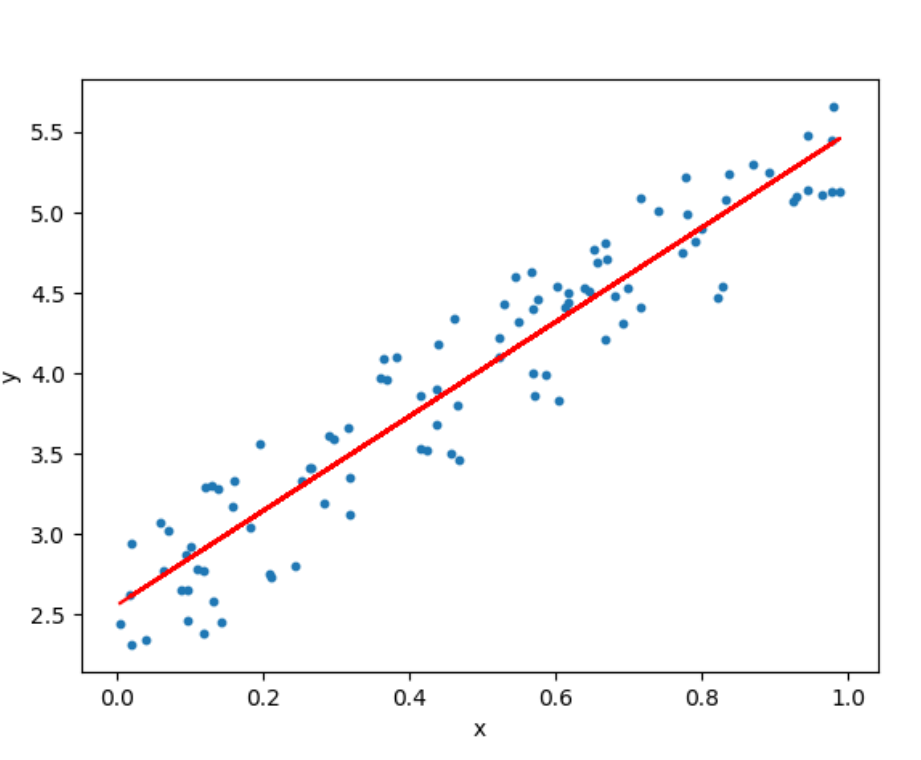
In the above diagram, the blue dots we see are the distribution of ‘y’ w.r.t ‘x.’ There is no straight line that runs through all the data points. So, the objective here is to fit the best fit of a straight line that will try to minimize the error between the expected and actual value.
Q5. OLS Stats Model (Ordinary Least Square)
Ans 5: OLS is a stats model, which will help us in identifying the more significant features that can influence the output. OLS model in python is executed as: lm = smf. ols(formula = ‘Sales ~ am+constant’, data = data).fit() lm.conf_int() lm.summary() we get the output below
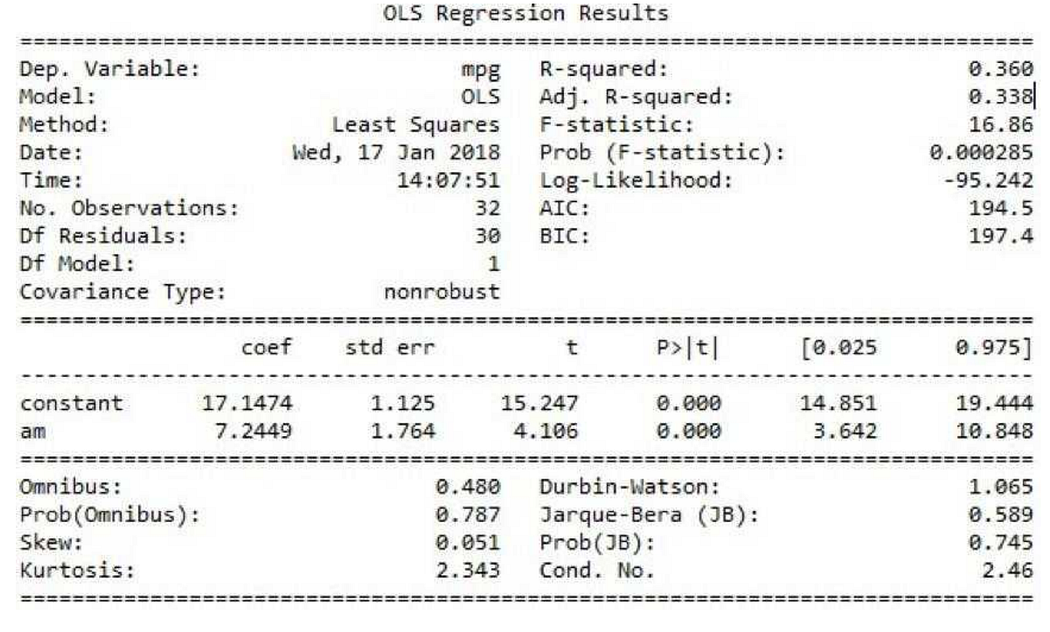
The higher the t-value for the feature, the more significant the feature is to the output variable. And also, the p-value plays a role in rejecting the Null hypothesis(The null hypothesis stating the features has zero significance on the target variable.). If the p-value is less than 0.05(95% confidence interval) for a feature, then we can consider the feature to be significant.
by — Subhanshu Tripathi
